I want you to open up the contact list on your phone, and see how many are in there. Of those hundreds of contacts, how many do you actually need today? Are they all saved under their correct names? Are you confident, all of them are active and up-to-date?
I looked at my contact list and realized I am carrying a ton of inaccurate, outdated contact information, including several people I don’t even remember ever knowing.
Now I know what you are thinking. “Shri, storage is dirt-cheap, why bother?”. I agree with you. It doesn’t matter much when it’s about personal contacts.
The point I’m trying to make is: if our personal contacts are so outdated or inaccurate, what do you think is the state of affairs when it comes to the enterprise contacts in your CRM or ERP?
Do you think your data is under control? How many times have you come across missing or incorrect data in your database? You must have been shocked to find the number of typos, jumbled formatting, outdated logs, and more such litter in your data, not to mention duplicates thrown in together. With such data, you:
- You probably don’t even know whom to call on your customer-side
- Do not have access to all client information
- Have to ask your customers for their equipment serial numbers repetitively
- Can’t enable your sales team with the right data to drive revenue
- Have heard of the benefits of Installed Base Data but not able to make full use of it!
Importance of Data Cleanup: What are the Consequences of Bad Data?
Data should bring clarity, not confusion. When information isn’t managed properly it becomes a liability. The simple rule of ‘Garbage in, Garbage out’ stands true in the case of data quality. When you feed bad data into your system you can’t expect good insights from it. Bad data will result in a string of negative consequences such as –
- Loss of revenue– Bad data will cost you money. Your sales and marketing teams won’t be able to target your audience effectively. Sales teams calling up wrong numbers, sending email blasts to invalid email addresses, sending out double emails due to duplicate data, ending up in the spam folder, etc will all result in loss of revenue to your organization.
- Loss of productivity – Business processes are highly dependent on data quality. If your teams work with bad data, they end up calling or working on things that don’t give out any promising outcomes, and hence your teams lose productivity. Inaccurate information hampers the decision-making process. So, instead of achieving the set targets or acquiring new customers, your teams end up cleaning and fixing your data which directly aids to their loss of productivity.
- Loss of stickiness/customer engagement – Knowing your customer always helps. If you always have even the tiniest bits of records or histories handy your customers end up being happy that you know all their details. No one likes to go back to their records and check the serial number, warranty expiration dates, last service review- every single time someone from your organization calls. Whenever your teams call your customer with incorrect information, it hampers your entire organization’s reputation.
Inaccurate or bad data is the cause of many such problems, which can easily be taken care of with better data quality management. So, how do you know if your data is clean or if you too are dealing with the problem of bad data?
So, how should an Industrial OEM assess Data Quality?
The first and foremost step before actually starting the data cleaning process is to assess the data quality. This assessment will give you a precise idea of how bad your data really is! It will also help you determine where your bad data is coming from so that you can avoid those data sources or prioritize fixing them.
Let’s start by analyzing the quality of your data. You can start by asking the following questions:
- Is the data valid and does it fit your formatting rules?
Validity of your data is vital when it comes to determining your data quality. Proper formatting can reduce the repetition of entries and structural errors. Wrong information can end up in the wrong cells when importing data. Deciding on a single format for the contact name, address, phone number, company name, and email address can help more than you know.
- Is your data accurate and true?
Accuracy and corrective data are the next steps. You can have the correct formatting and the data in the right cells. But it’s not really of any use of the data itself is incorrect. Now, this is a tough nut to crack because an algorithm can’t help you with that. If there occur to be frequent mistakes in the data assembly, that means the source of the data needs to be revisited.
- Is your data complete?
People may choose to skip a field while filling out any online form. That leads to blank spaces and hence bad data. You may personally need to find out the missing data because assuming basic information won’t just cut it. Can you believe over 63% of your data has missing values on average? At least one field is missing in this data. These missing values can be in terms of the absence of information or plain simple misplacement of data while handling it. This 63% of incomplete data might result in loss of revenue in huge proportions.
- Is your data consistent?
A database giving two different contact details for a data entry with the same name and same email address is suspicious. Such entries not only hinder the consistency of the database but also prove to work unfavorably for your sales rep. Data inconsistency also includes having data entries with misleading information. There can’t be a 22-year-old employee with 10 years of manufacturing experience.
The journey begins with assessment: 4 steps to assess your data quality
Assessing data quality is a complex process, but it’s a much-needed one. After assessing the data quality, the next step is to ensure your data collection process aligns with the high-quality data that you have collected. The way you collect your data has to be in line with your requirements. If this is not put in place, you will definitely end up tethering bad-quality data.
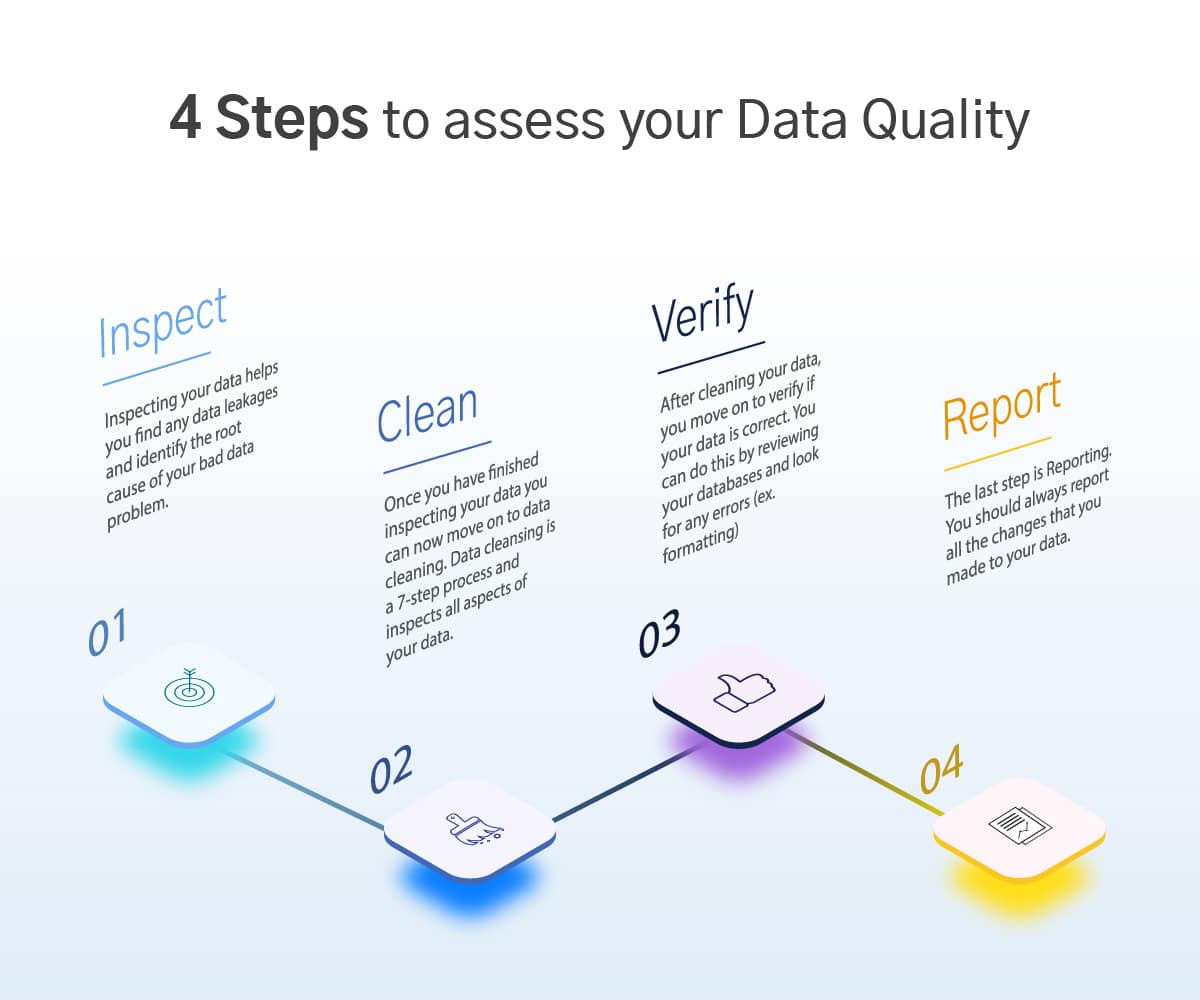
Inspecting, cleaning, verifying, and lastly, reporting of the data management process can be a good segmentation of the process to ensure squeaky clean healthy data.
These are the 4 steps that can help you ensure that your data is clean and ready to use:
1. Inspect
Inspecting your data helps you find any data leakages. If you do not inspect your data before starting the cleaning process, you tend to ignore the root cause of your problem, hampering your data management process.
2. Clean
Once you have finished inspecting your data you can now move on to data cleaning. This complete process has been broken into 7-steps and has been explained in the next section.
3. Verify
After cleaning your data, you move on to verify if your data is correct. You can do this by reviewing your databases and looking for any formatting errors. This helps you verify if your data is clean.
4. Report
The last step is Reporting. You should always report all the changes that you made to your data which is currently stored with you. These reports should contain all the details regarding any formatting rules you changed, what errors you identified, what was the root cause of such errors, or even how many times you identified such errors.
Reporting can also be used to identify the source of your data; where you have pulled in your quality leads from, do these leads qualify, and identify if there is any pattern that helps you convert leads.
What does Data Cleansing mean for Industrial OEM?
Data cleansing includes identifying, amending, or removing any data within a contact list which is incomplete or incorrect, or basically, unnecessary. No organization wishes for outdated data as it may prove harmful to the company’s efforts of improving productivity. Current, accurate, and regular updating is the way to enhance one’s data management efforts.
Data cleaning is a time-consuming process and quite wearisome at that. We should not ignore the fact that no amount of heavy algorithms can cut out the effort that cleaning the data takes. You can DIY, alternatively, you can cut down the time it takes and the resources you will spend considerably by taking the help of industry experts (you can read more about how Entytle can help you here).
A 7-Step Data Cleansing Process for Industrial OEMs

- Remove irrelevant data: The primary step is removing irrelevant data. An HVAC company doesn’t need to know the contact’s hobbies or interests in the dataset. We need to avoid asking for insignificant details from the contacts.
- Data deduplication: Weeding out duplicates is another long task but one of utmost importance. Making sure we don’t have dupes of the same company in different formats will reduce the unnecessary load on the CRM and we can therefore avoid emailing or calling the same person which might give a leeway to an increased number of unsubscribes. Understanding how the data is duplicated is vital to avoid further mishaps in the CRM. Our reports show that on an average, 26% of your data is enriched after deduplication. That’s 26% of understanding clear opportunities and lesser load on CRM.
- Data type conversion: Type conversion is the process of converting one data type to another. There can’t be numericals in the name column. It has to be characters. Assigning each cell with a particular type will help in maintaining uniformity throughout the database.
- Data standardization: Standardizing the data with respective formatting, be it alignment, font size, font, uppercase or lowercase characters makes the data easier to read.
- Missing Values: Deciding whether to find out the missing data or scrapping it altogether is an important decision and depends on what part of the data is missing. For example, we can make do without the contact’s phone number if we have the email address. But in case the contact number and email address are both missing, it is safe to discard the entry as there won’t be any way to reach out to the contact.
- Eliminating Cross Data Set Errors: Eliminating the cross data set errors is the next step in the process. We have already discussed this when we were discussing the consistency of our data. Cross data set errors occur when multiple fields in the same contact data contradict each other.
- Removing Outliers: Outliers are the fields of data which don’t fit in the complete dataset. If any value in the given data is completely off from the rest of the set then it definitely points out that something in the data is wrong and needs to be corrected. Example: If someone has entered their age as 250, you can make an educated guess that this data is wrong. So, we need to take care that such outliers don’t ruin your data and we must get rid of those asap.
Data Cleansing or Data Enrichment generates revenue, gives clear opportunities, and helps with understanding data that are consistent in behavior. If we try to put a number to this statement, our reports say that industrial OEMs might need data enrichment of up to 47% in order to achieve reliable data quality. With the above-given steps, you can easily fix your data problem. You can also use tools like Entytle Insyghts which not only fix your data, they help you drive better insights and opportunities from your data.
Entytle’s Data Quality Engine unifies, cleanses, and organizes all your data by primarily integrating all your tools. To know more about Entytle’s Data Quality Engine, click here.
Frequently Asked Questions
- How do you asses your data quality?
Assessing your data quality is a vital step while considering data cleansing. Inspecting, cleaning, verifying, and lastly, reporting of the data management process can be a good segmentation of the process to ensure squeaky clean healthy data.
2. How do you know if your data is dirty?
Data Quality Assessment will help you get a clear idea of your data quality.
3. When should you clean your data?
Data Cleansing is a continuous process. You should start cleaning your data as soon as you import it. Data cleansing includes identifying, amending, or removing any data within a contact list which is incomplete or incorrect, or basically, unnecessary.